Caffe (an image feature extraction library) installation was finally successful this week. The possible reason for the problems faced was a conflict between Nvidia graphics driver and Ubuntu Desktop Environment. The server version of Ubuntu, which does not have desktop environment by default, was used instead of desktop version. Figure 1 is an extract showing that all the tests have passed, meaning a successful Caffe installation.

Figure 1: Successful Caffe installation
Caffe performance is better (approximate 11 times faster) when used with GPU instead of CPU [3]. According to Caffe official website (http://caffe.berkleyvision.org/), Caffe can process 60M images per day with a single NVIDIA K40 GPU. This is because GPU has thousands of cores that enable processing of image in parallel where CPU has few cores and would process it sequentially [1][2]. Image can be divided into small patches (m by n grid) and these small patches can be processed synchronously. Figure 2 below shows Caffe performance comparison when used with CPU vs GPU vs GPU with cuDNN (deep neural network library).
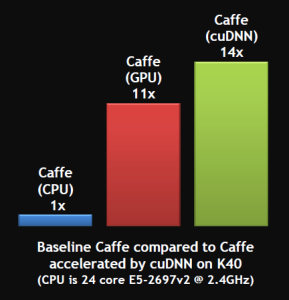
Figure 2: Caffe performance comparison (Source: http://devblogs.nvidia.com/parallelforall/wp-content/uploads/sites/3/2014/09/cudnn_caffe_performance-289×300.png)
I was planning to use my laptop as the developing machine and use a much more powerful server machine, which has caffe installed, at Insight Centre for full dataset process. Caffe library was only tested on few specific Nvidia graphic cards, excluding the one in my laptop, Thus, caffe CPU mode was used on my laptop. However, when processing full dataset on the server, caffe will automatically switch to GPU mode.
On Friday (27.02.2015) the AlexNet features (extracted using caffe library) for the Flickr dataset were planned to be published according to the official Flickr dataset website: http://www.yli-corpus.org/home/future-releases). This type of features were to be extracted from the query image using caffe library and the indexed Flickr image features searched to find similar images from which the tags could be extracted. However, the release date has been changed to 30th April, a week after my project submission deadline. This postponement means that the approach we selected (in week CW 6) can not be applied.
After discussion with my supervisor, we have altered our original solution to using LIRE image features (already released by Flickr) instead of AlexNet features.
LIRE is an open source Java library that extracts several low level features, such as MPEG-7 ScalableColor, ColorLayout, EdgeHistogram etc. from the input image.
What have also changed is that the features were meant to be hosted on Amazon cloud, which can be accessed directly, is now shared on Google Drive in the format of 9,921 compressed tar files. The total size of the dataset is 329 GB and approximately 1.5 TB after decompressing. This means that we need to process this data locally instead of on the Amazon Cloud as we have originally planned. It also means that processing this data require a lot of computational resources. After discussing with my supervisor, we decided that we may have to process a subset of the whole dataset depending on the the computer resources that are available to us. Whether to process the full dataset or a subset and the size of the subset is not determined yet. I will review some literature, ask for advice and experiment to find out how much data we can process.
I met my supervisor on Friday. We have discussed the progress since our last meeting, what I am working on at the moment and the next steps. I have also received some advice and clarifications on what I should include in different sections of the Final Delivery Documentation especially on the market analysis of the target market section. I will be posting progress on this as well.
This week the problem with caffe installation, that was stopping me from making progress on the project, has been fixed. However, this solution may not be applied now. Caffe extracts AlexNet features which will not be available from Flickr in my time frame and I need to change my approach.
In CW 10, I will install LIRE library and read the documents to learn how to use it. Hopefully it will not cause issues like caffe library, so I can still get back on my schedule.
Bibliography:
[1]. Gregg, Chris, and Kim Hazelwood. “Where is the data? Why you cannot debate CPU vs. GPU performance without the answer”. Performance Analysis of Systems and Software (ISOPASS), 2011 IEEE International Symposium on. IEEE, 2011.
[2]. Asano, Shuichi, Tsutomu Maruyama and Yoshiki Yamaguchi. “Performance comparison of EFGA, GPU and CPU in image processing”. Field Programmable Logic and Applications, 2009. FPL 2009. International Conference on. IEEE, 2009.
[3]. Larry Brown, 2014. “Accelerate Machine Learning with cuDNN Deep Neural Network Library” [Online]. Available from: http://devblogs.nvidia.com/parallelforall/accelerate-machine-learning-cudnn-deep-neural-network-library/ [Accessed on 1 March 2015]

{kind=link}
March 9th, 2015 at 12:42 pm
[…] discussed in the previous post, caffe cannot be used due to the delay of planned release date of AlexNet features. Thus, for the […]
LikeLike